cs3219-project-ay2122-2122-s1-g21
PeerPrep Technical Documentation

Made exclusively for CS3219 Software Engineering Principles and Patterns
Live Deployment URL [Deprecated]: https://www.peerprep.net/
Github Repository: [contact minglim@comp.nus.edu.sg for access]
Link to Video Demo: https://www.youtube.com/watch?v=7MXiDMZXg-4

Developers
Low Ming Lim
Lim Si Ting
Ye Jia Dong
Yoong Yi En
Contributions
| Name | Technical Contributions | Non-Technical Contributions |
|---|---|---|
| Low Ming Lim | Ming Lim handled all UI components associated with the project, from UI mockups on Figma to vue assets and site deployment. He is also responsible for integrating the client with our microservices such as user account management, matching and enabling video calls. Authentication services were also deployed via AWS cognito. | Authored the frontend portion of our technical documentation along with sections on design patterns and deployment. |
| Lim Si Ting | Si Ting handled the user account management microservice and AWS deployment for it. Handled configuration of AWS services (for i.e. route 53, certificate manager and load balancers), segregating these services into different subnet on the VPC. | Wrote individual portions on microservices,as well as NFR. Wrote MVT design patterns. |
| Ye Jia Dong | Jiadong handled the peer-programming page, as well as integration with the UI. Also deployed microservices on Google Cloud Run. Setup twilio for chat microservice and video conferencing features | Wrote individual portions on microservices, DevOps, and FR. |
| Yoong Yi En | Yi En handled the match microservice, and also question generation. Handled AWS deployment for match microservice. Set up CI/CD pipeline, configured auto scaling on ECS Fargate and conducted load testing | Wrote individual portions on microservices,as well as NFR. Did deployment documentation. |
1. Introduction
1.1 Background
Increasingly, students face challenging technical interviews when applying for engineering jobs. These are not easy to deal with without adequate hands-on practice. Even with the availability of several algorithmic practice platforms such as Leetcode, students still face issues with a lack of communication skills in articulating their thought processes out loud to an outright inability to understand and solve the given problems. Moreover, grinding practice questions alone can be tedious and monotonous.
1.2 Purpose
1.3 Project Scope
For the interview questions, we intend to scope them to a small subset of actual Leetcode questions, and we permit only two peers to be directly connected to each other per session. Future editions might include the ability to engage in group work with more than 2 individuals.
2. Overall Description
2.1 Product Perspective
2.2 Product Features
2.3 Operating Environment
3. Functional Requirements
3.1 User Account Management Service
| ID | Functional Requirements | Priority | Design Element |
|---|---|---|---|
| F-UAM-1 | The account management service must allow users to create a PeerPrep account using an email address with the “.edu” domain along with a password. | High | AWS Cognito |
| F-UAM-2 | The account management service must verify users’ email addresses before their account is successfully created. | High | AWS Cognito |
| F-UAM-3 | The account management service must allow users to sign into their accounts with their registered email and password. | High | AWS Cognito |
| F-UAM-4 | The account management service must allow users to reset their passwords with email verification. | High | Aws Cognito |
| F-UAM-5 | The account management service should allow users to logout from the question difficulty selection page. | High | Log out button |
| F-UAM-6 | The account management service shall allow users to change their passwords if they can verify their old passwords. | Medium | AWS Cognito |
| F-UAM-7 | The account management service must allow matched peers to view the user’s basic information (from completing practice questions). | Medium | Home page |
| F-UAM-8 | The account management service shall allow users to modify basic information about their profiles. | Low | Update profile page |
| F-UAM-10 | The account management service shall allow users to view an updated score computed from their number of successful matches. | Low | Home Page |
3.2 User Matching Service
| ID | Functional Requirements | Priority | Design Element |
|---|---|---|---|
| F-RTD-1 | The user matching service will allow users to choose their practice questions from at least 3 difficulty levels (easy, medium, hard). | High | Front End page allows users to pick a difficulty level then click ‘Match Now’ |
| F-RTD-2 | The user matching service must match users to peers based on their selected difficulty level (easy, medium, hard) when they request for a practice session. | High | User Matching algorithm matches users based on their selected difficulty level and position in the queue |
| F-RTD-3 | The user matching service must allow users to cancel their search for matches when they are not yet allocated a match by the system. | High | Front End ‘Cancel Match’ button while waiting for match |
3.3 Chat Service
| ID | Functional Requirements | Priority | Design Element |
|---|---|---|---|
| F-C-1 | The chat service must allow users to communicate with their peers via text in real-time during the practice sessions. | High | Twilio |
3.4 Video Service
| ID | Functional Requirements | Priority | Design Element |
|---|---|---|---|
| F-V-1 | The video service must allow users to communicate with their peers via video in real-time during the practice sessions. | High | Daily Video |
| F-V-2 | The video service must allow users to mute themselves during the practice sessions. | High | Daily Video |
| F-V-3 | The video service must allow users to share their screens in real-time during the practice sessions. | Medium | Daily Video |
3.5 Peer Programming Service
| ID | Functional Requirements | Priority | Design Element |
|---|---|---|---|
| F-PP-1 | The peer programming service must allow users to view their own whiteboard editor in real-time to solve practice questions. | High | Firepad connects to Firebase real-time database to stream updates live. |
| F-PP-2 | The peer programming service must allow users to edit their own whiteboard editor in real-time to solve practice questions. | High | Firepad connects to Firebase real-time database to stream updates live. |
| F-PP-3 | The peer programming service must compile the user’s submitted code. | High | Judge0 Compilation Service |
| F-PP-4 | The peer programming service must display the output of the compilation of the user’s code. | High | Retrieving Judge0’s compilation results |
| F-PP-5 | The peer programming service must allow users to quit practice sessions and return them to the question difficulty selection page. | High | “End Session” button |
| F-PP-6 | The peer programming service will allow users to highlight specific portions of their code. | Medium | Firepad and CodeMirror Editor |
3.6 Application Client
| ID | Functional Requirements | Priority | Design Element |
|---|---|---|---|
| F-AC-1 | The application client must timeout when users are not allocated a match after a fixed period of time. | Medium | Timer |
| F-AC-2 | The application client must allow users to resume sessions when users navigate away from the peer-programming page without ending the match. | Low | Cognito token storage |
| F-AC-3 | The application client must allow users to continue their ongoing sessions when users refresh the page. | Low | Cognito token storage |
4. Non-Functional Requirements
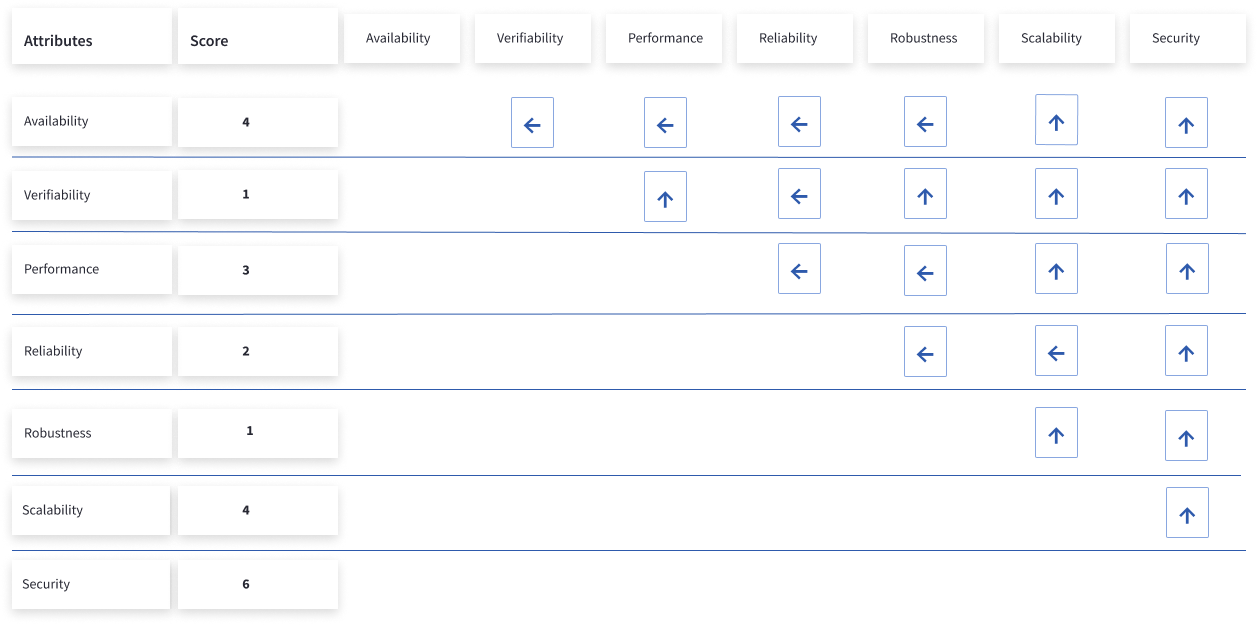
We prioritized our NFR as per the table above. We can see that security, scalability and availability are most important.
4.1 Security NFRs
| ID | Description | Priority | Design Element |
|---|---|---|---|
| N-SEC-1 | All important communication between client and server should be encrypted with the latest TLS standards | High | HTTPS on AWS ALB and Route 53 |
| N-SEC-2 | All microservices should be configured such that only authorized parties and services are allowed to access the backend and databases | High | AWS VPC |
| N-SEC-3 | The webpage should be secure to SQL Injection, XSS, CSRF, DDOS | Medium | AWS Cognito |
Our website is secured with HTTPS certificate which is issued by AWS certificate manager. This would ensure that the traffic is secured with the TLS standards. For our microservice hosted on AWS, it is split into private and public subnet. The backend services are in the private subnet and have their API authenticated with JWT token. This ensures that only relevant authorized party is able to communicate with the backend.
4.2 Scalability NFRs
| ID | Description | Priority | Design Element |
|---|---|---|---|
| N-SA-1 | The system should support 500 users accessing the website | High | ECS Fargate |
| N-SA-2 | The system can accommodate up to 250 pairs in the collaborative coding space at any given time | High | ECS Fargate |
| N-SA-3 | The system can provide matchmaking services to up to 250 users at any given time | High | ECS Fargate |
For NR N-SA-1, we load tested with a total of 1000 request to our www.peerprep.net with 100 request per second for 10 seconds. The return response for all 1000 packets are 200 OK which means that our system is able to accomodating 1000 concurrent users accessing our system. Hence, it is capable of supporting 500 users and even more users on our website.

Diagram 4.2.1.1: Load testing of NFR N-SA-1
For NFR N-SA-2, we sent 50 request second for 10 seconds to our matching service API endpoint. All 500 packets responsed with 201 status code meaning that they have successfully ping the endpoint. Hence, this shows that our system is able to support 500 users searching for their matches.

Diagram 4.2.2.1: Load testing of NFR N-SA-2
4.3 Availability NFRs
| ID | Description | Priority |
|---|---|---|
| N-AV-1 | The system should ensure a 99.98% server uptime for peak periods ( Monday - Friday, 5pm - 12am ) | High |
| N-AV-2 | With a stable internet connection, our web application should guarantee a load time of fewer than 11 seconds for end-users | High |
| N-AV-3 | The system should provide textual synchronizations for our collaborative text-field service with a latency of fewer than 5 seconds upon detecting user input | High |
| N-AV-4 | Users who fail to find a match within a 30-second window should timeout from their matchmaking session. | High |
| N-AV-5 | The system should be fully optimized for access via Chrome browsers | High |
5. Architecture Decisions
5.1 Architectural Diagram
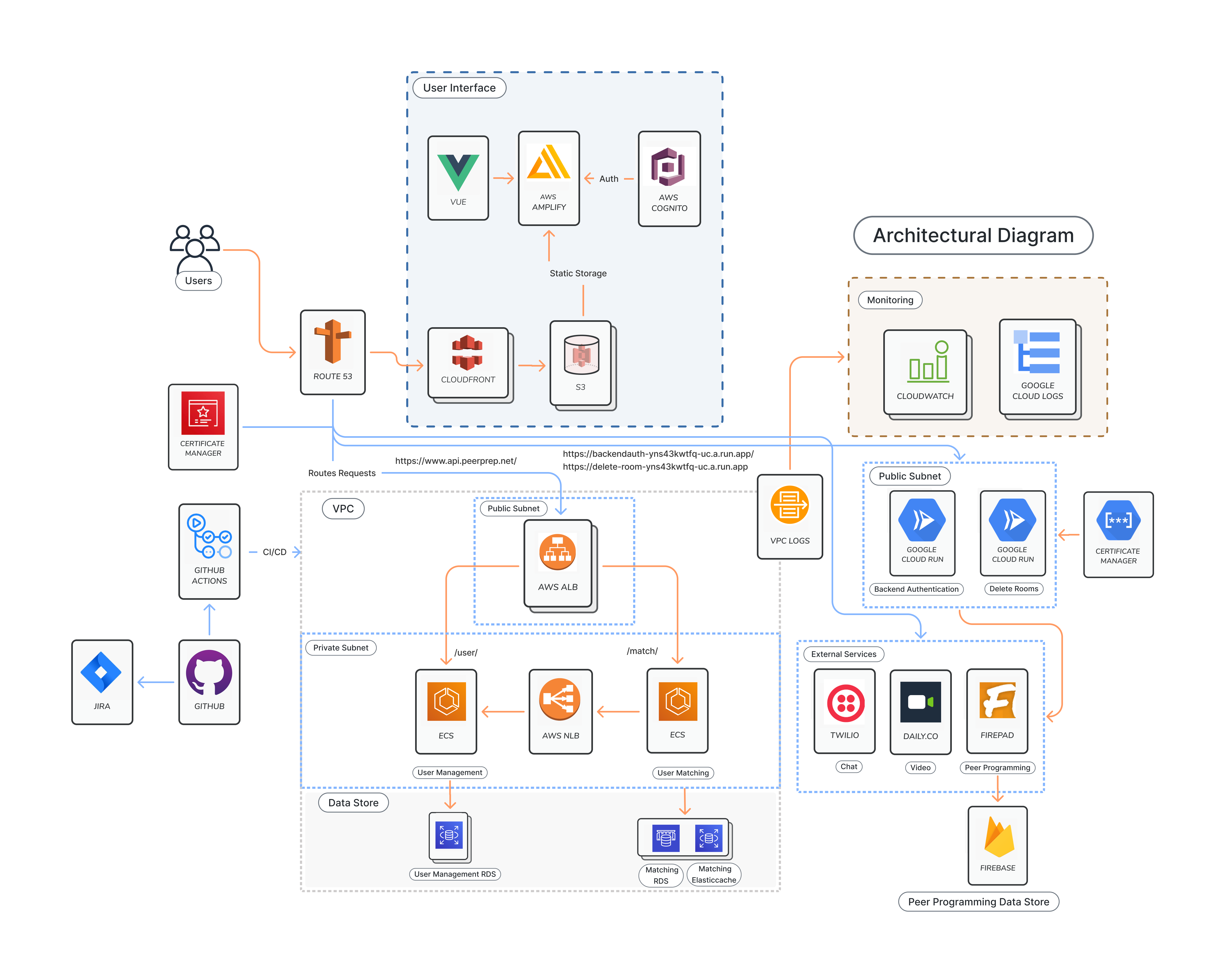
5.2 Architectural Decision
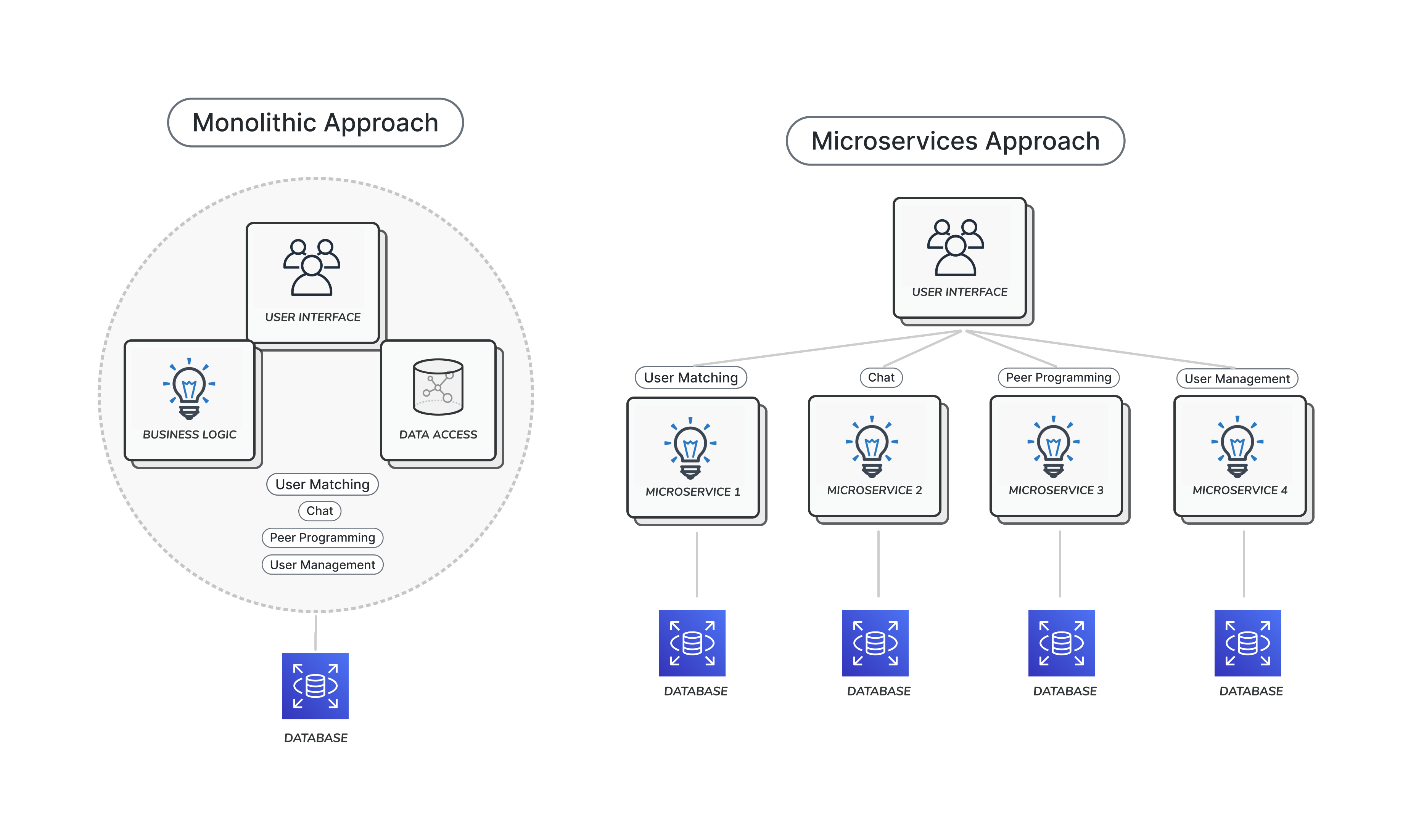
5.2.1 Architectural Decision 1 - Microservice over Monolithic
| Potential Issues Considered |
|---|
| Potential heavy coupling of different modules |
| Difficult to extend additional helpful tools with a highly coupled approach |
| Testing might be challenging due to dependencies between modules |
| Development will be difficult to integrate between different team members in a monolithic approach |
| Ensuring service quality does not degrade in meeting real-time requirements |
| Challenging to integrate different frameworks together within one single application |
Final Architecture Decision
We decided to proceed with a Microservice architectural design over a Monolithic one.
Justification
On the point of coupling and testing, we considered that as a team working on the project together, it was important that each team member should be able to isolate and test his/her own module without having to rely significantly on the implementation of other team members. This will not only speed up development, but also ensure smooth testing of each individual component. By reducing the number of dependencies between modules, we also reduce the possibility of regressions occurring between code changes. A microservice approach will allow us to separate the modules within its own containers, and expose APIs for inter-process communication.
Moreover, we considered the possibility that future versions of our services will need to be easily extended to fulfill additional features. This could include supporting additional programming languages, advanced compilation features or even video call services. All these point us towards a microservice architecture, where additional services can be easily provisioned, with minimal modifications to existing services. On the other hand, a monolithic architecture is likely highly coupled, and this presents difficulties in integration and extension.
In terms of meeting the real-time requirements of our application, we need an architecture that can scale rapidly to support load. Otherwise, an influx of users might compromise the system, and lead to performance being compromised for the rest of the users. Microservices that are deployed on the AWS ECS cluster are able to be auto scaled depending on the load, and this was an attractive option for us to be able to configure our own scaling requirements.
On the other hand, we also considered the disadvantages of a microservice approach. While microservices might present additional complexity, such as in designing the communication channels between the different services, we will attempt to reduce complexity in other areas such as by making use of automatic scaling mechanisms provided by AWS (e.g. ECS Fargate / Lambda), as long as costs are not prohibitively high.
5.2.2 Architectural Decision 2 - Redis Caching
| Potential Issues Considered |
|---|
| The queue in User Matching service requires repeated and regular accesses of data (reads and writes). If hosted in a database, performance will be severely compromised |
| Users in the queue should timeout if no match is found after 30s |
| Many users trying to find a match in a short period of time |
| Memory representation on databases (i.e. data structures) can be complicated to manipulate |
| Caches, on the other hand, need to be carefully managed to ensure that only the most updated data is retrieved |
| Redis caches can only store data that is not larger than memory, so huge datasets cannot be cached |
Final Architecture Decision
We decided to adopt a Redis Cache to store the user matching queue in-memory.
Justification
The user matching queue only needs to persist in-memory, and they would need to be read and written to several times in order to ensure that the queue is updated in real time. Hence, an in-memory cache would drastically improve latency and real-time performance by reducing the number of read and writes that would have to be made to the relational database. In fact, the latency for an update to the AWS ElastiCache hovers around 300-500 microseconds versus double-digit milliseconds for a traditional relational database.
Furthermore, Redis provides an unique advantage - the ability to store data through simpler and foundational data structures. There is minimal internal data complexity, and this makes Redis much easier to utilise and manipulate. Redis also allows easy expiration of keys, allowing us to effortlessly implement our 30s timeout on users in the queue.
We considered the limitations of the Redis cache and concluded that it was highly unlikely that our user queue would grow to surpass that of our in-memory storage, as data is textual in nature and we also expire items in the queue after 30s.
5.2.3 Architectural Decision 3 - AWS Application Load Balancer
| Potential Issues Considered |
|---|
| There should be a way to route traffic to the different microservices. |
| Routing traffic should be done with minimal security considerations. |
| Requests should be authenticated. |
| There should be support for invoking lambda functions. |
| Websockets should be supported to allow for our chat services to communicate. |
| Load-balancing should be available. |
Final Architecture Decision
We decided to proceed with a Application Load Balancer.
Justification
We needed a single point of entry for the microservices, so that all traffic that is destined for the microservices can be processed, authenticated with the same protocol. A single point of entry and exposure to external requests also means minimal security risks, as any security threats would have to all pass through the application load balancer. Furthermore, the ALB makes our product more extensible, as the addition of new microservices would simply require additional routing rules within the ALB.
Having considered the differences between an API Gateway and an ALB, we decided to with the ALB as it supports the major features of our microservices (lambda, websockets), as well as provides more significant load-balancing capabilities.
5.2.4 Architectural Decision 4 - AWS ECS Fargate
| Potential Issues Considered |
|---|
| Auto-Scaling Capabilities |
| Simple deployment |
| Simple CI/CD |
| Pricing |
Final Architecture Decision
We decided to adopt AWS ECS Fargate.
Justification
AWS Fargate is a serverless, pay-as-you-go compute engine that lets us focus on building applications without managing servers. AWS Fargate is compatible with both Amazon Elastic Container Service (ECS). Without Fargate, we would have to manually configure and run our EC2 instances. We would also have to manually configure auto-scaling. Fargate removes the need to own, run, and manage the lifecycle of our compute infrastructure.
Using Fargate, we simply connect our ECS Cluster to our container in AWS Elastic Container Registry (ECR), create a Task definition and Fargate takes care of the spinning up of Tasks. It also makes CI/CD very straightforward. We just have to use Github Actions to authenticate with AWS then automate the creation and pushing of a container image to ECR. From there we use Github Actions to create a new version of our current Task definition with our new image and Fargate handles the rest of the deployment using that Task definition.
Fargate also easily and automatically scales the number of tasks run depending on our specified policy. With just a few settings to configure, auto-scaling for our microservice on Fargate can be set up in 5 minutes.
However, one draw back would be pricing. Fargate charges by per vCPU per hour and per GB memory per hour. As Fargate automates many processes, we do not have exact control over how much vCPU or memory is used and therefore unable to fully control the pricing.
5.2.5 Architectural Decision 5 - AWS Network Load Balancer
| Potential Issues Considered |
|---|
| There should be a way for the different microservices to communicate. |
| Load-balancing should be available. |
| Pricing |
Final Architecture Decision
We decided to proceed with a Network Load Balancer.
Justification
The microservices needs a way for them to communicate with each other, hence, we needed a service discovery tool to help us with that. Our microservices that need to communicate with each other are hosted in an AWS VPC and run as an ECS Fargate task. ECS do offer their own service discovery, however, due to our financial strain, we needed a solution that could deliver the same functionality for free. It would be beneficial if the service discovery is also able to load balance in the event that a particular microservice receives an excessive number of requests.
Hence, we have employed the use of an internal network load balancer instead of ECS service discovery. The network load balancer is able to help us load balancer, free cost and serve as a point of entry for microservices to communicate with each other.
6. Design Patterns
6.1 Model View Controller Pattern (MVC)
Used predominantly to support the storage, retrieval and display of information to end users, we decided to adopt the MVC pattern for our User Account Management Service ( MS-1 ).
6.1.1 Rationale for choosing the MVC Pattern
The following details the benefits that motivated our adoption of this pattern.
| Benefits | Justifications |
|---|---|
| Better modularity and reusability | MVC enforces the separation of concerns principle. |
| Accelerates developmental processes | As coupling between the Model, View and Controller components are reduced, each team member will be able to work on each of the 3 component concurrently. This paves the way for parallel development and potentially allows us to complete development 3 times faster. |
| Potentially reduces code duplication | As web applications are constantly evolving, we may plan to create multiple Views for our model to serve different devices. In light of this possible project enhancement, MVC reduces the need for code duplication as it separates our display from our business logic and data components. |
| Improves our ability to conduct unit tests | Adopting the MVC pattern helps us reduce coupling and improve cohesion by separating the input, output and processing components. |
| Enhances UI modification capabilities | Since components are more loosely coupled, changes in the View components will less likely require changes in the Model component. This is essential as UI changes are usually frequent for web applications. |
Given below is an example of how we aim to apply the MVC pattern to our implementation of the User Account Management Service ( MS-1 ).

Diagram 6.1.1.1: High level view of our MVC Pattern implementation
- A user views the application in the browser.
- The user can then interact with our web application (eg. clicking a link/update his profile information).
- The browser then sends this request to the router.
- The router will then call a specific controller based on the UI event that occured.
- The controller will then interact with either the model to update data or the View to update the UI based on the event detected.
- The View component may thus fetch data from the Model component as a result.
- Finally, the View component updates the browser and the user sees the required changes on the UI.
6.2 Model View Template Pattern (MTV)
We have employed the use of Django Rest Framework for our User Account Management Service ( MS-1 ) and User Matching Service ( MS-2 ). MTV is the design pattern adopted by Django with Model component working together with data ( for i.e. database). The View component serve as a bridge which interacts with the Model and Template components respectively. Finally, the Template component renders the data and creates the Django user interface.
6.2.1 Rationale for choosing the MTV Pattern
The following details the benefits that motivated our adoption of this pattern.
| Benefits | Justifications |
|---|---|
| Better modularity and reusability | MTV abide by the separation of concerns principle. |
| Suitable to build large scaled application | This is critical in order for us to be able to further extend and scale our application in the future. |
Given below is an example of how we apply the MVT pattern to our implementation of the User Account Management Service ( MS-1 ).

Diagram 6.1.1.1: High level view of our MTV Pattern implementation
- The frontend sends a GET request “https://www.api.peerprep.net/user/getAllUsers/”.
- The request will be forwarded to django’s URL which will then search for getAllUsers view.
- The view conponent will fetch the data from the Model component which in turn read data from the User Management Database.
- Afterwhich, the View component will pass the data to Template component which renders the data into web pages using HTML, CSS and Javascript.
- Finally, the View component returns the rendered page and frontend is able to view and access the data.

Diagram 6.2.1.2: Relevant file directory of user management service
6.3 Publisher-Subscriber Pattern
To facilitate real-time communication between our users via our Chat Service ( MS-2 ), we have decided to employ the Publisher-Subscriber Pattern as the primary Messaging Pattern for our application. The Publisher-Subscriber Pattern is a popular messaging pattern that utilizes the ØMQ message queuing library which provides sockets for message communication.
6.3.1 Rationale for choosing the Publisher-Subscriber Pattern
The following details the benefits that motivated our adoption of this pattern.
| Benefits | Justifications |
|---|---|
| Supports easy modification of individual components | Upon the adoption of a topic-based system, Publishers and Subscribers will follow a loose coupling as it is not necessary for them to know of their mutual existence. Subscribers are only required to know the topics that they are subscribing to while publishers have the responsibility of defining these topics. |
| Gives us the opportunity to enable group chats in future | This can easily be done by increasing the number of subscribers |
| Performance scalability | Pub-Sub allows the capitalization of message caching and parallel operations. |
Given below is an example of how we aim to apply the Pub-Sub pattern to our implementation of the Chat Service ( MS-2 ).

Diagram 6.3.1.1: High level view of our Pub-Sub Pattern implementation
- Publishers can be modelled as PeerPrep users who are sending messages.
- Subscribers can be modelled as PeerPrep users who are receiving messages.
- Events can be modelled as a Chat instance that users are currently in.
- Based on diagram 6.2.1.1, we see the possibility of expanding our chat system beyond 2 recipients as seen from event topics B and C where there are more than 1 recipient for messages sent in that chat instance (also known as event topic)
6.3.2 Other Pattern Considerations
Before we decide to adopt the Publisher-Subscriber Pattern for our Chat Service ( MS-2 ), we also considered another design pattern for this service.
Exclusive-Pair Pattern
Similar to the Pub-Sub pattern, the Exclusive-Pair pattern is a popular messaging pattern used for software messaging services.
How it works
Adopting the ØMQ message queuing library, this pattern models behavior similar to regular sockets by supporting bidirectional communication between each exclusively paired socket. Further, sockets within each pair will not store any states and can only be connected to one other socket.
Hence, this design pattern is sufficient for our messaging needs as PeerPrep users will be undertaking algo questions in pairs based on current design requirements.
However,
We felt that the adoption of this pattern will greatly limit our ability to enhance and provide for future features. For instance, we may allow the creation of chat groups where users can add multiple friends to discuss algo questions together. We may also allow multiple users to join the same algo practice session in future should we upgrade our matching service.
In light of these expansion possibilities, adopting the exclusive pair pattern would thus severely hamper our future development.
6.4 Adapter Design Pattern
The adapter pattern act as a link between two incompatible interfaces, allowing objects with different interfaces to communicate with one another. This adapter design pattern is employed by Firepad, a collaborative text editor used to build our peer programming service, to communicate with their Firebase as well as their underlying editor.
7. Tech Stack
| Component | Application or Framework | |
|---|---|---|
| Frontend | VueJS | |
| Backend | Django | |
| Database | PostgreSQL hosted on AWS RDS | |
| Cache | RedisCache hosted on AWS ElastiCache | |
| Cloud Providers | AWS, Google Cloud | |
| Monitoring | VPC Flow Logs, CloudWatch Logs | |
| CI/CD | Github Actions | |
| Orchestration Service | ECS Fargate | |
| Load Balancing | AWS Application Load Balancer | AWS Network Load Balancer |
| Project Management Tools | JIRA |
8. Devops
8.1 Sprint Planning
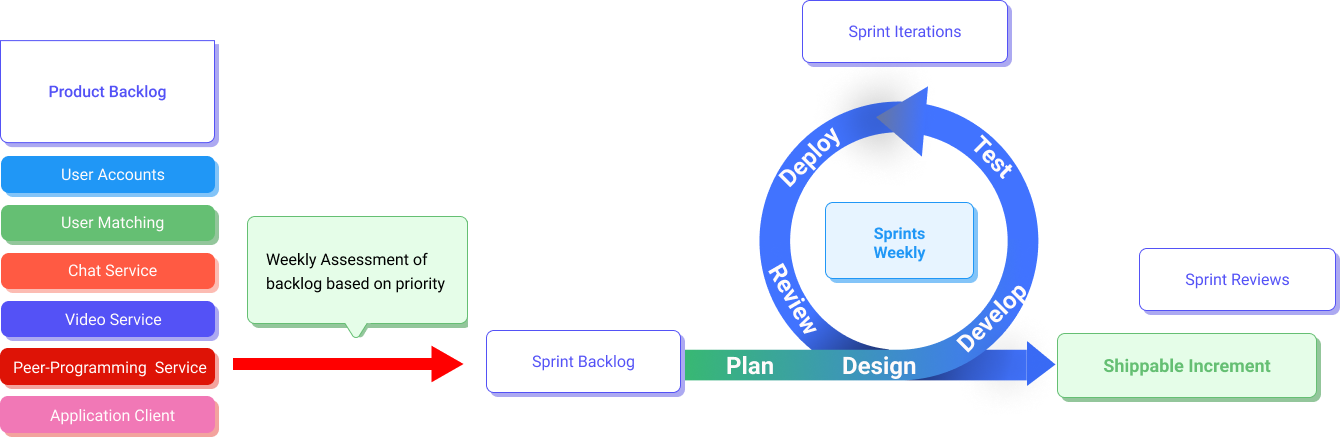
We adopted an agile Scrum approach in the development of our software. We first confirmed the product backlog as shown below, before we allocated the tasks into sprint backlogs for the sprints that we planned over the 8-9 weeks that we had. The first 4-5 sprints were focused on completing functional and non-functional requirements, while the remaining 2-3 sprints were dedicated to deployment and documentation workloads. Each sprint lasted for a week. For every two days, we had very short stand-ups to catch up on each other’s progress and also resolve any difficult issues that have been affecting team members. Every weekend, we also hold a longer meeting to plan for subsequent sprints, and also determine the tasks that have to be reallocated from the previous sprints.
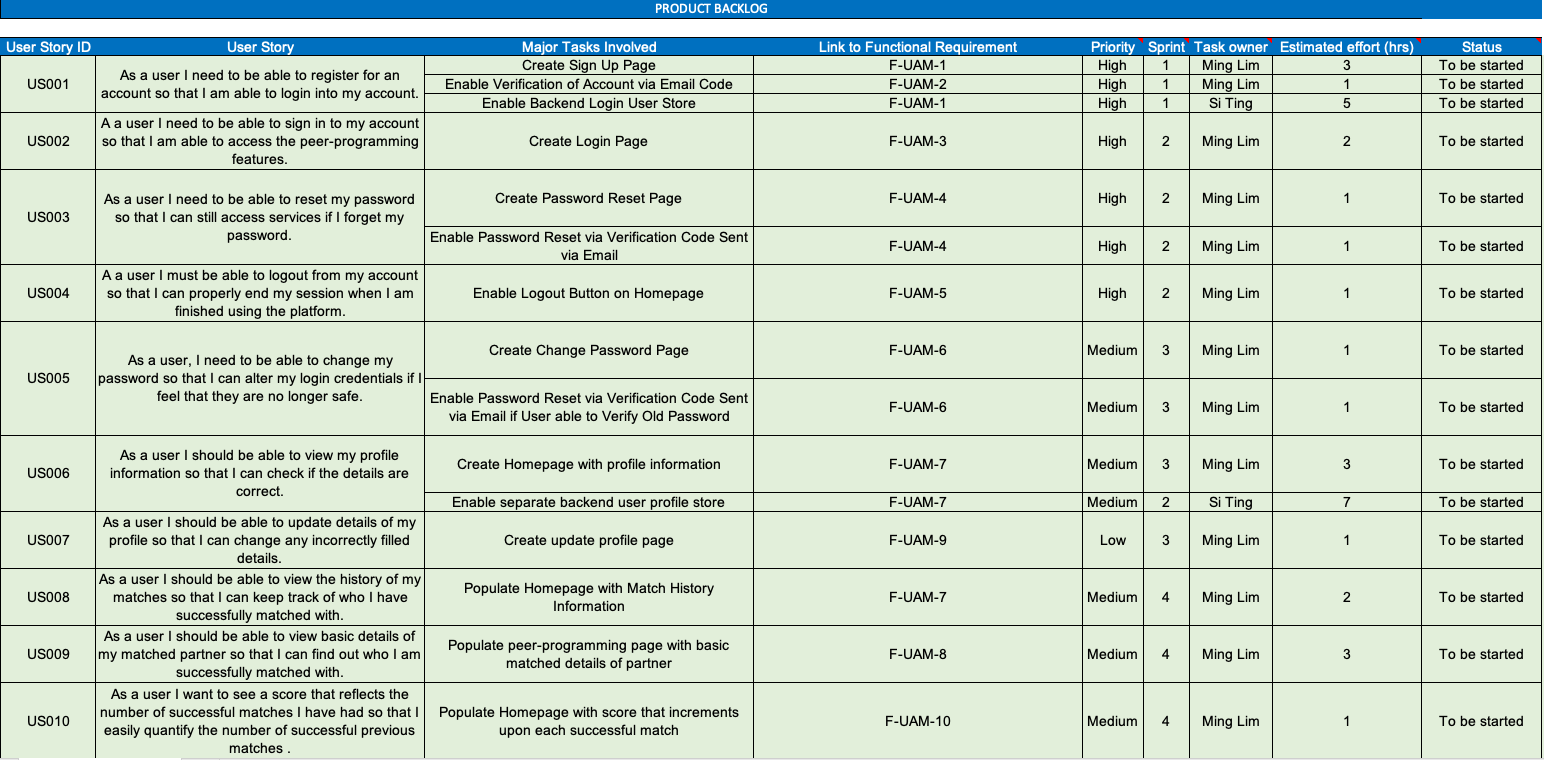
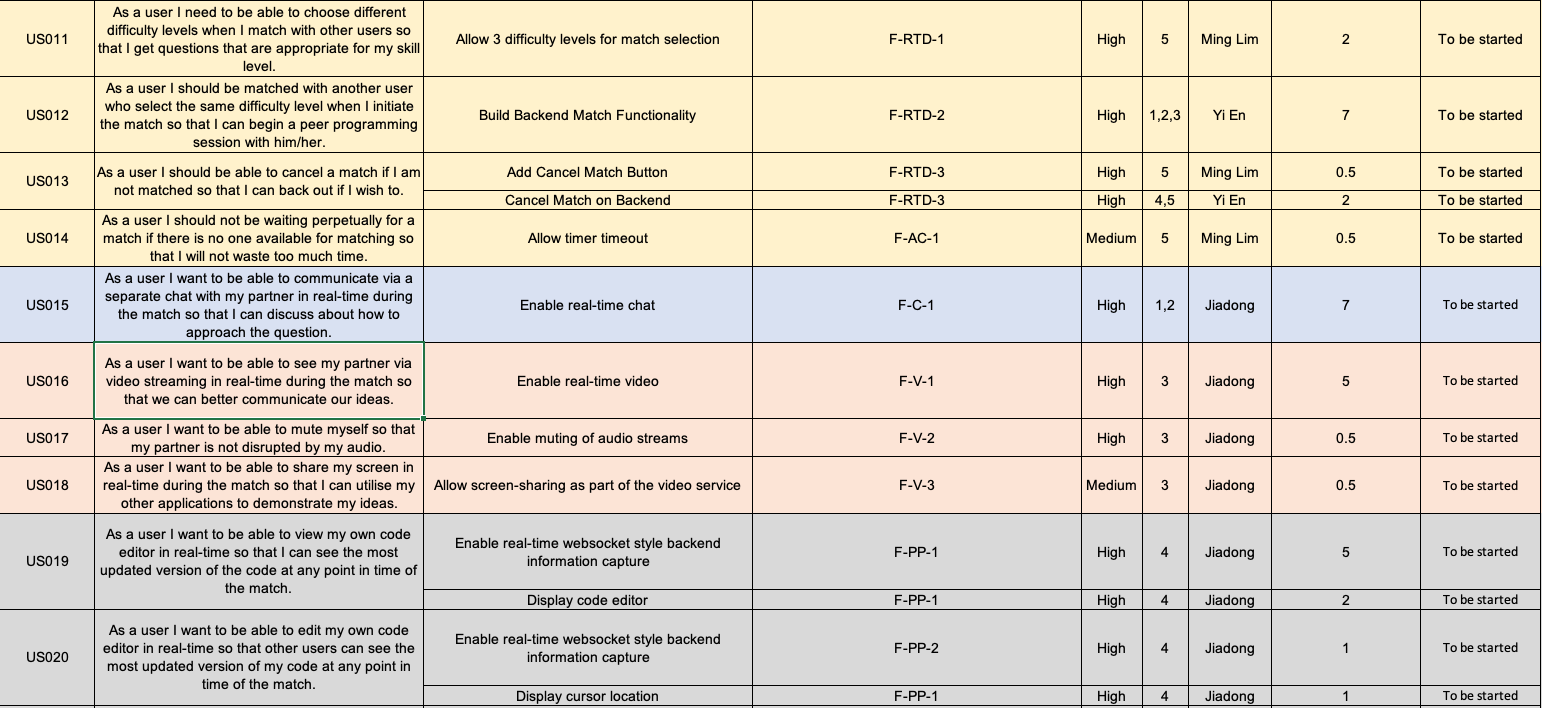

We first came up with an overall product backlog. It contains user stories, major tasks that are tagged to these stories, as well as traceability back to our functional requirements. This was then distributed to individual sprints on Jira, like the following:
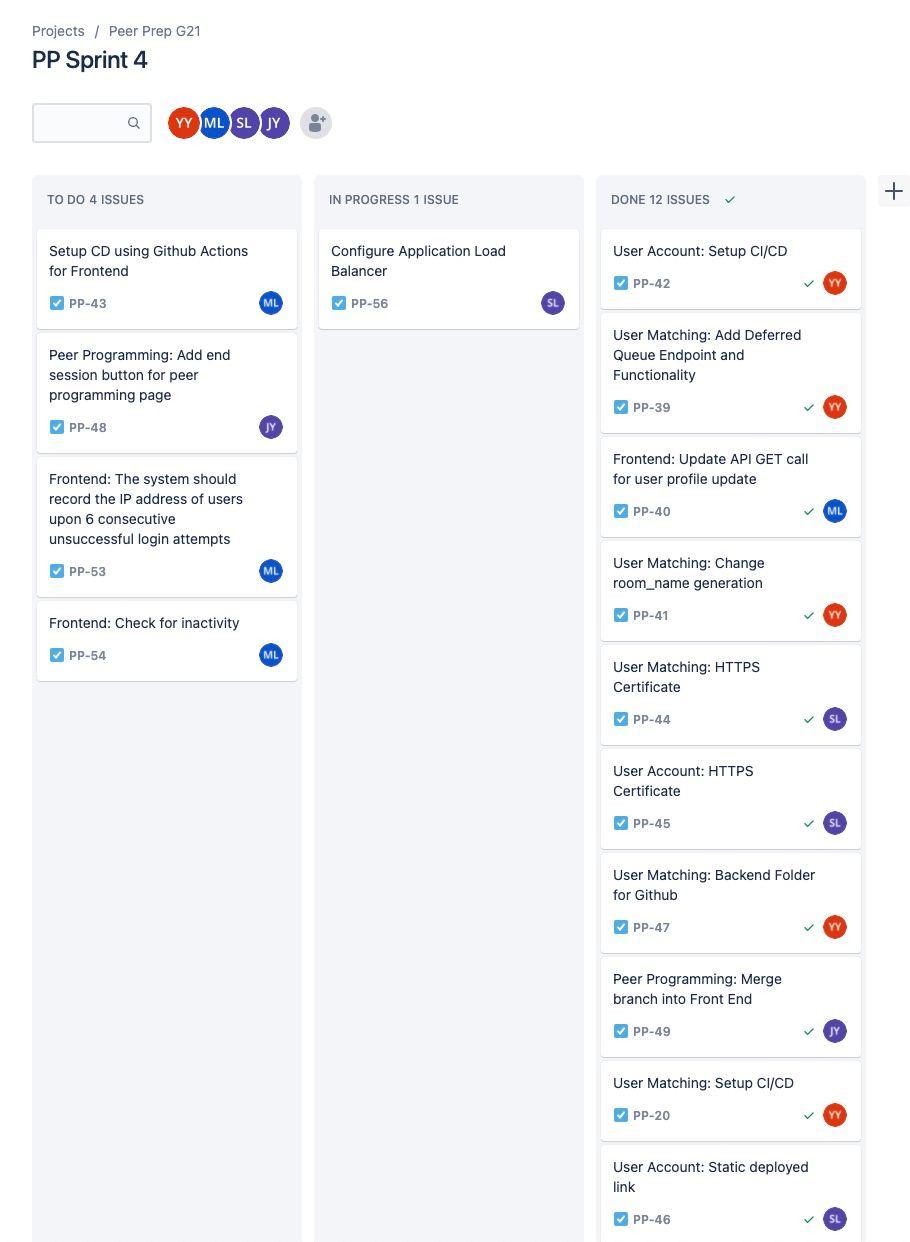
This also provided us with an Agile board to be able to keep track of open issues, in progress issues as well as resolved issues. Any new issues that surfaced during sprints were also added to the issue boards within Jira, and then added to the sprint backlogs of the subsequent sprints.
For each sprint review at the end of every week, we conducted the following activities:
- Confirm on progress of entire team
- Make decisions on key matters
- Determine which tasks/issues need to be moved to the next sprint
- Coordinate integration if necessary (especially API endpoints)
- Identifying areas of improvement and how we can work more efficiently together
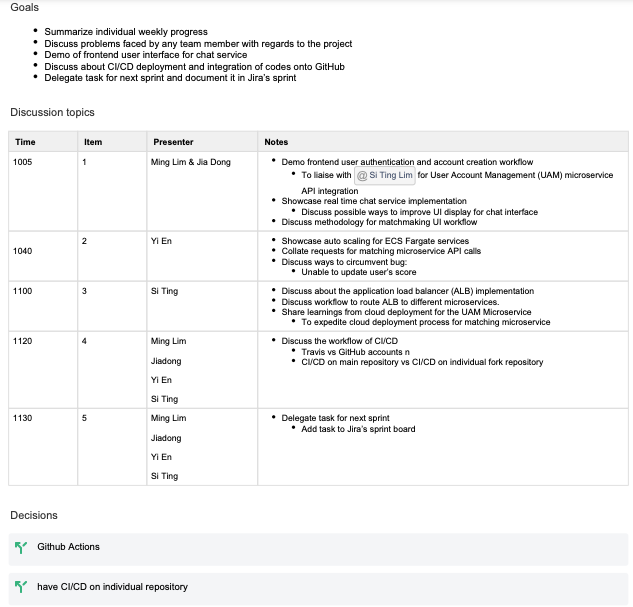
Meeting notes are kept for each sprint review and stored on Confluence. An example of meeting notes that we took during a sprint review is appended below:



8.2 Frontend Deployment
PeerPrep’s frontend has been built with Vue JS and Bootstrap Vue and runs on Node 13.7.0
Local Deployment
- First, clone our team repository from https://github.com/CS3219-SE-Principles-and-Patterns/cs3219-project-ay2122-2122-s1-g21
- Download and install
Node 13.7.0from https://nodejs.org/en/download/releases/ on your local machine. - After the successful installation of Node, launch a terminal and run
node --versionto check your Node version. Please ensure that it is running on v13.7.0. - Navigate to the root directory of our cloned repository.
- Run
cd ./frontend/vue-frontendto navigate to the frontend folder. - Install all dependencies by running
npm installoryarn install - As our backend microservices have been deployed to the cloud, to effectively test all frontend features, please add the following file
aws-exports.jsfile manually for the required credentials. While the file will usually be added to our git.ignore, for simplicity we have uploaded the file for download here link - Please add the
aws-exports.jsfile downloaded in the previous step to thevue-frontend/srcfolder as seen below:

- Now, launch the frontend locally by running
npm run servein the terminal. - Upon a successful launch, you will be able to see the ip address in which you can access our site via a browser as seen below:

- You may choose to launch our site via either the provided local or network addresses. This should open our landing page as seen below:

- Congratualtions! You may now try accessing our features by creating an account via the
Sign Upbutton!
Publishing changes to AWS Amplify
- To publish local changes to our amplify service, you will need to configure and
pip install aws cli - After installing
aws cli, you will need to configure your credentials by runningaws configure. However, for security reasons, we will not be able to provide you with our AWS Console credentials. - However, for completeness, upon configuring your aws credentials you may run
amplify publishto deploy local changes to the cloud. - A successful deployment will yield the following message:

- The frontend will then be accessible via the following link: https://www.peerprep.net/
8.3 CI/CD using Github Actions
As ECS Fargate is used to deploy our microservice, we just need a Task definition. Upon every update, we have to update the Task definition with the latest container image on our repository in AWS Elastic Container Registry (ECR).
We first have to place all the secret variables in Github Secrets. For example, our AWS credentials, AWS RDS database credentials, AWS Cognito credentials, etc.
We will also have to have a file of our Task definition in json format. This can be obtained from the AWS Command Line Interface (CLI) or from their web interface.

Obtaining Task Definition JSON from AWS Web Interface
</br> The steps to CI/CD with Github Actions are then as follows:
- Configure AWS credentials
- Login to Amazon ECR.
- Build, tag, and push image to Amazon ECR
- Fill in the new image ID in the Amazon ECS task definition
- Deploy Amazon ECS task definition
Define all these steps in a workflow file. On a commit, Github Actions will automatically trigger this workflow.

Main part of workflow in Matching and User Management Services
AWS Fargate then handles the rest of the deployment after the Task definition has been updated.
9. Microservices
We rely on a variety of different microservices in order to provide different functionalities within our applications. Some of these microservices are hosted in-house by us, while others are external third-party APIs that we integrate with. We outline the current arrangement in the table below:
| Microservice | In-House / Third-Party | External Service Relied On |
|---|---|---|
| User Management | In-House | NA |
| Real-Time Matching | In-House | NA |
| Delete Rooms | In-House | NA |
| Real-Time Peer Programming | Third-Party | Firebase Real-time Database |
| Real-Time Chat | Third-Party | Twilio |
| Real-Time Video | Third-Party | Daily Video |
| Code Compilation | Third-Party | Judge0 |
9.1 General Authentication Framework (For Chat, Video and Peer Programming Services)
9.1.1 Basic Description
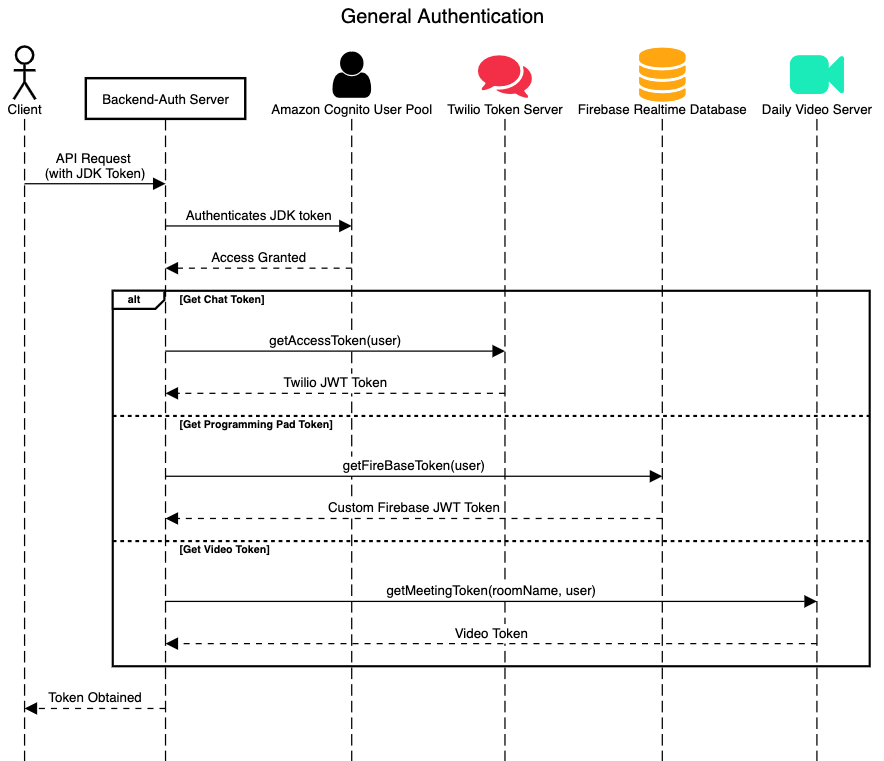
As security is a key non-functional requirement, our authentication framework to gain access to the respective microservices involves a two-step process. First, we deploy a backend authentication server that serves as a “Facade” for clients to send their API requests to. All clients’ requests must contain a header with the JDK token that they are issued by AWS Cognito upon successful login to their user accounts. This JDK token is then verified with Cognito to determine its validity (tokens can expire), before the user is then authenticated to access the APIs that the backend authentication server provides.

If users attempt to access the backend authentication server by providing an invalid JWT JDK token, then the response will indicate a 401 status, together with an error message and the expiry date of the token inputed. If no token is inputed in the request header, then an error message “Access Token missing from header” will be displayed. Upon successful authentication, users will be able to access any of the following APIs to be able to obtain respective tokens to authenticate their access to the Twilio chat, Firebase realtime database as well as daily video servers.
| Service | API Link | Request Type | Compulsory Parameters |
|---|---|---|---|
| Twilio Chat | /auth/user/:user | GET | Username |
| Firebase Real-time database | /firebaseauth/user/:user | GET | Username |
| Daily Video Server | /video/createroom/:roomName/:userName | GET | Room Name, Username |
9.1.2 Endpoints
9.1.2.1: GET Firebase custom authentication token endpoint:
Gets a Firebase access token to access firebase-realtime database services
- [GET] HTTP request: https://backendauth-yns43kwtfq-uc.a.run.app/api/firebaseauth/user/{userid}
- userid refers to the unique userid that was defined for each user (i.e. the email address)
- Authentication: Pass in AWS Cognito JDK token as part of request header under a “accesstoken” key

On success, the token will be returned.
9.1.2.2: GET Twilio conversation token endpoint:
Retrieves a Twilio token that grants access to Twilio services (i.e. client SDK)
- [GET] HTTP request: https://backendauth-yns43kwtfq-uc.a.run.app/api/auth/user/{userid}
- userid refers to the unique userid that was defined for each user (i.e. the email address)
- Authentication: Pass in AWS Cognito JDK token as part of request header under a “accesstoken” key

On success, the token will be returned.
9.1.2.3: GET Daily Video Room meeting token endpoint:
Deletes a Firebase editor node from the Firebase real-time database
- [GET] HTTP request: https://backendauth-yns43kwtfq-uc.a.run.app/api/video/createroom/{roomname}/{userid}
- roomname refers to the unique roomname that was allocated for each match room
- userid refers to the unique userid that was defined for each user (i.e. the email address)
- Authentication: Pass in AWS Cognito JDK token as part of request header under a “accesstoken” key

On success, the video token will be returned together with the details of the created video room.
9.1.2.4 Deployment
Backend Authentication Server Deployed Base API Link: https://backendauth-yns43kwtfq-uc.a.run.app/api
The backend authentication server is an Express.js server deployed on Google’s Cloud Run service. Cloud Run is a cloud-managed service that allows us to deploy highly scalable containerized applications on a fully managed serverless platform. We outline the following benefits of using Cloud Run below:
- Cloud Run automatically scales running container instances depending on the real-time load profile.
- Entirely serverless, which means that it is more cost efficient for our use case, since the backend authentication server would likely only be active for a fraction of the total time an user is active online.
- Simpler developer console compared to AWS, which makes it easy to use and deploy
- Abstracts away all infrastructure management (i.e. there is no need to manage and specify scaling specifics, which is required in AWS’s EC2 instances)
- Continuous Deployment possible with Github Actions
- Since we rely on the Firebase Realtime Database for our peer-programming services, locating our backend authentication server within Google’s cloud framework makes it more secure.
- In terms of cost, cloud run provides 2 million free requests every month, whereas AWS’s comparable Fargate services has entirely no free-use limits
9.2 Chat Service
We make use of Twilio’s conversation service to power our chat. The service runs via WebSockets, and allows us to configure real-time chat messaging between connected clients.
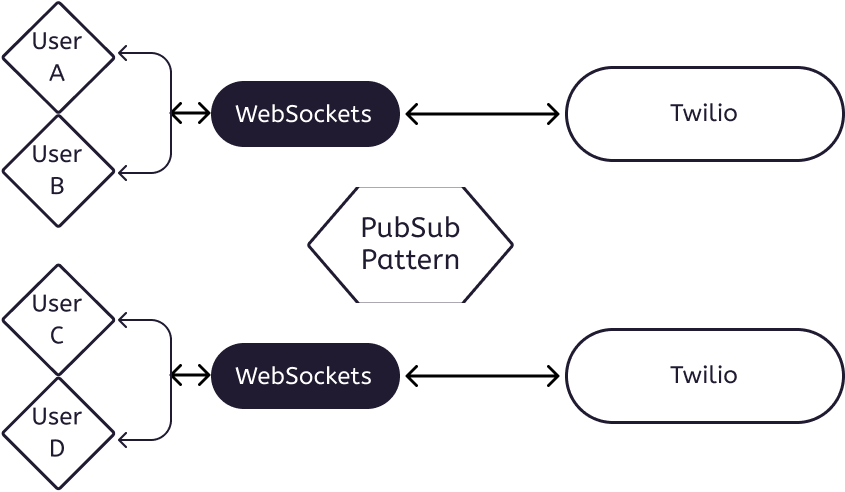
From the diagram above, we can see that Twilio makes use of the PubSub design pattern to relay messages sent by either users to each other, and there is no need for the clients to continuously poll a server for any new messages sent. This reduces latency, and also the total number of requests that need to be sent to ensure real-time communication.
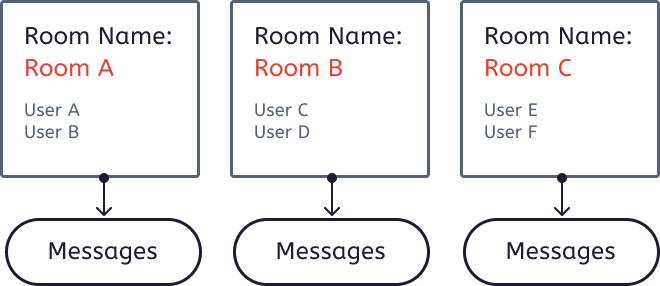
All of Twilio’s conversation rooms are identified with a unique name, so that users can join the same room as their matched roommate, and begin their peer programming session. Each room also stores an unique identifier, unique name, number of participants, creator name, as well as date created and date updated information. Chat messages will also be stored specific to each unique room. This ensures that users will not misadvertently join the wrong conversation room, or be shown the wrong chat messages, as all room names are unique and allocated at the matching phase.
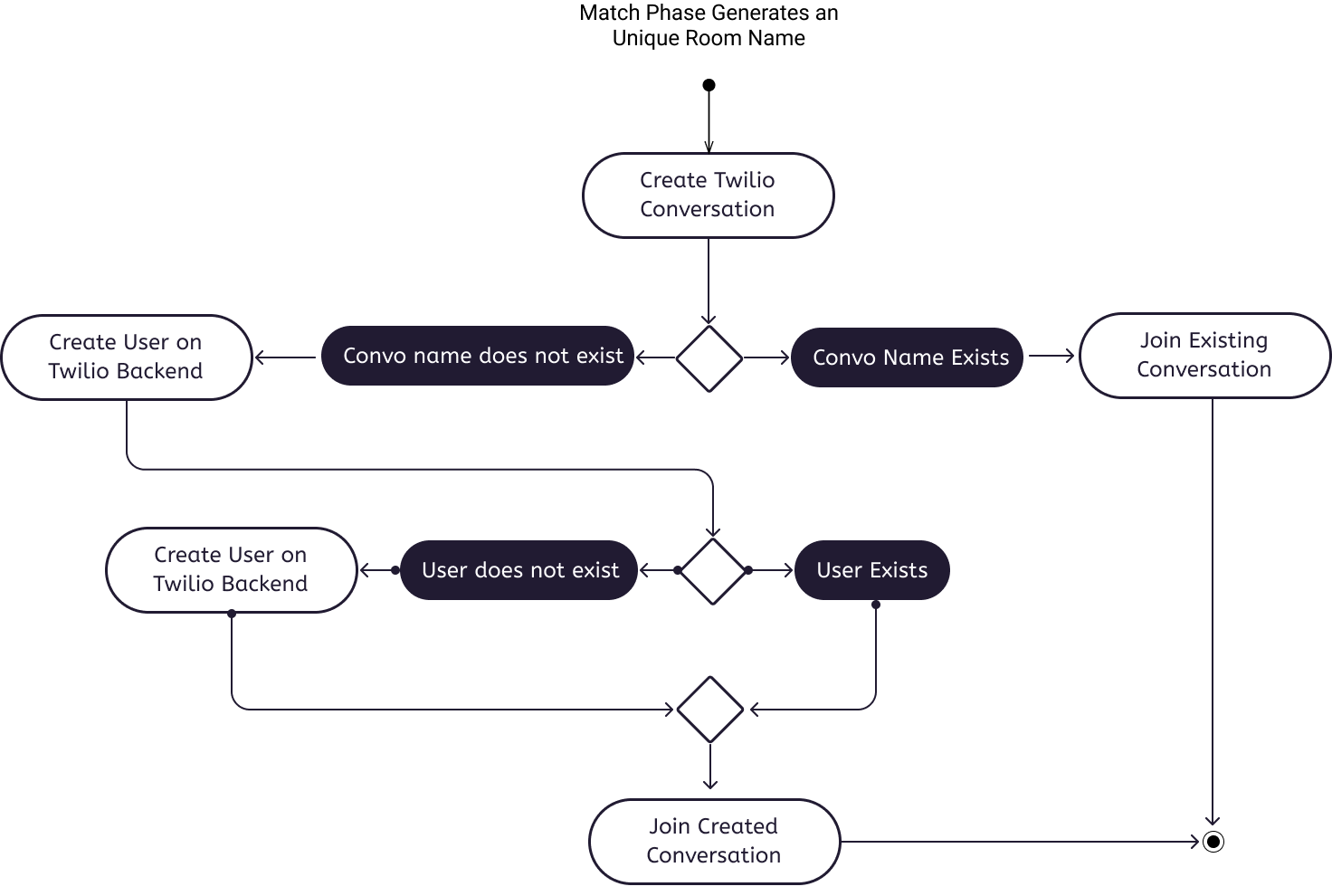
Using the activity diagram above, upon a successful match, the match service would return both matched clients their unique room name, which they then each use to create a Twilio conversation, together with their unique usernames. If a room with the same name already exists, then the user will join the existing conversation immediately. Otherwise, Twilio will verify if their usernames already exist in the Twilio user database. If it does not exist, then the name will be added to the user database within Twilio. Thereafter, the users will proceed to join their created conversation room as well. This flow ensures that conversation rooms are not duplicated, or over-written.
sendMessage: function() {
this.activeConversation.sendMessage(this.messageText)
.then(() => {
this.messageText = "";
})
}
The above code snippet shows how a message is sent to the Twilio database. The sendMessage() function is invoked upon the press of the button to send the message. Twilio’s SDK functions are then relied on to successfully deliver the message to the Twilio database.
this.activeConversation.on("messageAdded", (message) => {
this.messages = [...this.messages, message];
});
Whenever there is a new message received, it will also be automatically appended to the message list, and reflected on the UI.
9.3 Editor Service
The Editor Service can be divided into two different components as follows:
- Frontend: CodeMirror powers our collaborative code editor.
- Backend: Firepad and the Firebase Real-time Database powers our backend data storage.
We justify the choices of these tools as follows:
CodeMirror
| Alternative | Justification |
|---|---|
| Ace Editor | While the Ace Editor is extremely similar to CodeMirror, it is slightly more complicated to develop with. |
| Google Docs / Any other collaborative editing textpad | Text editing services are more suitable for document editing, and do not carry similar features as code editing. (i.e. linting) |
Advantages of using CodeMirror
- It has support for multiple languages (i.e. C, Java, Python…)
- There are many third-party add-ons that can improve user experience (i.e. automatic inclusion of brackets)
- Themes can be changed easily.
Firebase Real-time Database
| Alternative | Justification |
|---|---|
| Custom designed ActiveMQ Message Broker | ActiveMQ / RabbitMQ message brokers might be too advanced for our use case. These are extremely tedious to configure. |
| Pubsub mechanism (i.e. Kafka / Redis) | Redis has limited in-memory space, and configuration is similarly tedious. |
More importantly, Firepad and Firebase provides the following advantages:
Advantages of using Firebase Real-time database
- It is more reliable and persistent than a web-socket solution, despite latency between 10x slower. Our priority is on scalability and availability.
- Firebase provides a more secure environment than a custom web-socket implementation. Authentication procedures are already available and built-in. Security is also our key focus area.
- Firebase is a no-sql database, which allows for sharding and scaling to multiple databases should the situation call for it.
- Free usage limits are reasonable.
Advantages of using Firepad
- It is natively integrated with Firebase, which means that it is serverless. We can achieve real-time collaboration with no server-code.
-
It is easily integrated with the frontend (CodeMirror) to allow for code-editing experiences.
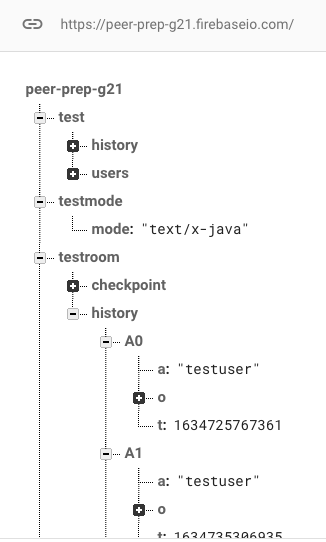
Taking a look at how the Firebase real-time database is structured, there are two main components: the mode, and the room. The room is appended with an unique room name and stores all changes that are made to the code editor. History is persisted until the end of the peer programming session. The mode stores the real-time language choice that both users have chosen. For example, if both users agree on Java, then the mode will similarly be persisted to the real-time database. This helps to ensure that both users are programming in the same language at any point in time of the peer programming session.
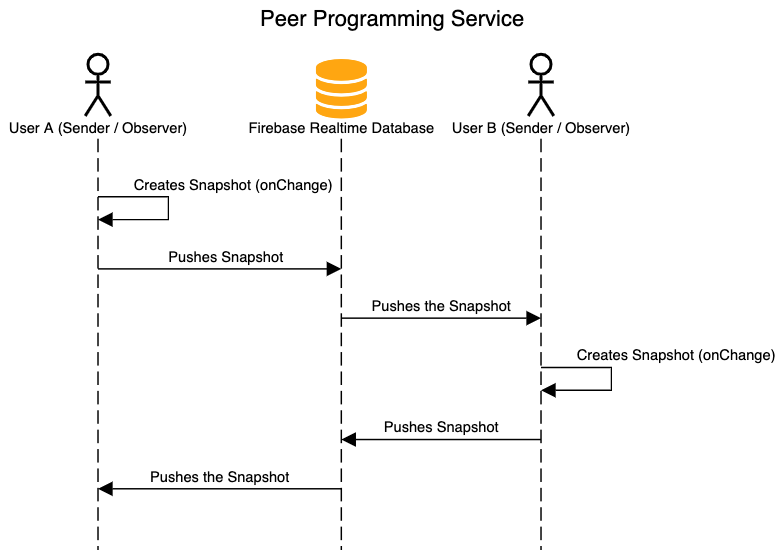 Here, we can see how an update is propagated to all peers in real-time. Whenever there is a change in the contents of the code editor, the client’s code editor will capture a snapshot of its current state, before pushing it to the Firebase Real-time database. The same snapshot will then be pushed to observers that are subscribed to the same “room” (i.e. the other matched user) and replace the contents of his / her code editor. The same thing happens when the other user now makes a change to his / her code editor. Resultingly, both the selected modes, as well as the contents of the code editor are synced in real-time.
Here, we can see how an update is propagated to all peers in real-time. Whenever there is a change in the contents of the code editor, the client’s code editor will capture a snapshot of its current state, before pushing it to the Firebase Real-time database. The same snapshot will then be pushed to observers that are subscribed to the same “room” (i.e. the other matched user) and replace the contents of his / her code editor. The same thing happens when the other user now makes a change to his / her code editor. Resultingly, both the selected modes, as well as the contents of the code editor are synced in real-time.Wew support the following four language modes are supported on our CodeMirror editor. The default mode when users first begin their session will be set as Javascript. Users can toggle to change the language at any point in time, but the code editor will be reset (i.e. all written code will be lost).
- C
- Python
- Javascript
- Java
9.4 Code Compilation
Endpoint URL: https://judge0-ce.p.rapidapi.com/submissions
Our peer-programming page incorporates basic code compilation features for the four languages that we support. We rely on the Judge0 service, which is a robust, scalable, and open-source online code execution system. Some of the reasons why we chose Judge0 are outlined below:
- Judge0 is easily deployable due to its modern architecture.
- Judge0 is also scalable, depending on the number of requests.
- Easy to use documentation
- Compilation and execution are sandboxed.
- Error messages are displayed in a verbose manner.
- Flexibility due to the availability of multiple parameters.
- Supports wide-ranging languages (60+)
We decided to rely on the deployment of the Judge0 container on RapidAPI’s service, which provides managed API endpoint services with auto-scaling capabilities.

The diagram above shows how Judge0 works. First, when code compilation is required, the client will have to initiate a first request to send the code to Judge0’s service via a POST API call. Judge0 will then return the client with a token, which the client can then utilise in order to check the status of his / her previous submission. Once the submission has been compiled and executed, the status will update, and the client can then obtain the output of the compilation. This two-step process means that compilation of code can be largely asynchronous. The client does not have to wait for Judge0 to be finished with compilation before moving ahead with other tasks. It can simply send the request, process other information, and then only poll for the output at a later date and time. We set a time limit of 2 seconds, as well as memory and stack limits to prevent users from impacting the overall functionality of the Judge0 service. This is unlikely to happen, given that most programming interview questions are set precisely to encourage students to think of solutions with the least space complexities, and which are also reasonable to solve within a short interview session.
9.5 Video Service
Our video service relies on Daily.co’s video service running on WebRTC to deliver video streaming services to both users. The token that the user obtains from the backend authentication server is tied to only the room that the user is supposed to join. Hence, the token cannot be used to access other meeting rooms, which may not be privy to the user. Users simply have to call a createAndJoinRoom(roomName, userName) method, in order to initialize the video room. An iFrame object is returned, which is then embedded directly onto the peer-programming page.
9.6 Delete Rooms
Hosted Link: https://delete-room-yns43kwtfq-uc.a.run.app
This is a basic Express.js server written to enable the clearing of rooms from the external services after each match has successfully ended. This ensures that there are no rooms left behind that can compromise both security, as well as latency for other users (since there is an overall cap on the number of rooms that we can set up on external services). Rooms do not need to persist in memory, since we do not store the history of the codes, chats and video logs for any subsequent display.
The endpoints that are exposed in the Delete Rooms service is outlined below:
9.6.1: DELETE Twilio Rooms endpoint:
Deletes a Twilio conversation room from the Twilio database
- [GET] HTTP request: https://delete-room-yns43kwtfq-uc.a.run.app/api/conversations/delete/{roomname}
- roomname refers to the unique roomname that was allocated for each match room
- Authentication: Pass in AWS Cognito JDK token as part of request header under a “accesstoken” key
9.6.2: DELETE Daily Video Rooms endpoint:
Deletes a Daily video room from the Daily database
- [GET] HTTP request: https://delete-room-yns43kwtfq-uc.a.run.app/api/video/deleteroom/{roomname}
- roomname refers to the unique roomname that was allocated for each match room
- Authentication: Pass in AWS Cognito JDK token as part of request header under a “accesstoken” key
9.6.3: DELETE Firebase node endpoint:
Deletes a Firebase editor node from the Firebase real-time database
- [GET] HTTP request: https://delete-room-yns43kwtfq-uc.a.run.app/api/deletefb/room/{roomname}
- roomname refers to the unique roomname that was allocated for each match room
- Authentication: Pass in AWS Cognito JDK token as part of request header under a “accesstoken” key
9.7 User Account Management Service
The User Account Management Service is built with Django Rest API Framework and it handles signing up of users as well as storing and retrieving user information.

Diagram 9.1.1.0. Sample Example Of Sequence diagram
9.7.1 Supported Endpoints
All endpoints are authenticated and authorized with AWS Cognito JWT Token as a Bearer Token to confirm the identity of a valid user. All request body formats are JSON.
9.7.1.1: ADD Users endpoint:
Adds registered user’s email and username into the user account database
- [POST] HTTP request: https://www.api.peerprep.net/user/addUser/
- Authorization Type: Bearer Token

Diagram 9.1.2.1: Sample Example Of JSON Body
Diagram 9.1.2.2: Sample Example Of Success JSON Response
9.7.1.2: GET a particular users endpoint:
Get a users’ email, username, score, faculty, year of study, course and bio < br/>
- [GET] HTTP request: https://www.api.peerprep.net/user/getUser/
- Input should be pass through query parameter

Diagram 9.1.2.3: Sample Example Of Query Params

Diagram 9.1.2.4: Sample Example Of Success JSON Response
9.7.1.3: GET all users endpoint:
Get all users’ email, username, score, faculty, year of study, course and bio < br/>
- [GET] HTTP request: https://www.api.peerprep.net/user/getUser/

Diagram 9.1.2.5: Sample Example Of Success JSON Response
9.7.1.4: UPDATE user score endpoint:
Increment user score by the given score < br/>
- [PUT] HTTP request: https://www.api.peerprep.net/user/updateScore/

Diagram 9.1.2.4: Sample Example Of JSON Body

Diagram 9.1.2.6: Sample Example Of Success JSON Response
9.7.1.5: UPDATE user profile endpoint:
- [PUT] HTTP request: https://www.api.peerprep.net/user/updateScore/

Diagram 9.1.2.7: Sample Example Of JSON Body

Diagram 9.1.2.8: Sample Example Of Success JSON Response
9.8 User Matching Serivice
The User Matching microservice stores all the matches, the programming questions and users match history. Users are matched based on their position in the User Matching queue and by the same question difficulty level. If a user is unable to find a match partner within 30 seconds, the request will timeout and the user will be removed from the queue.
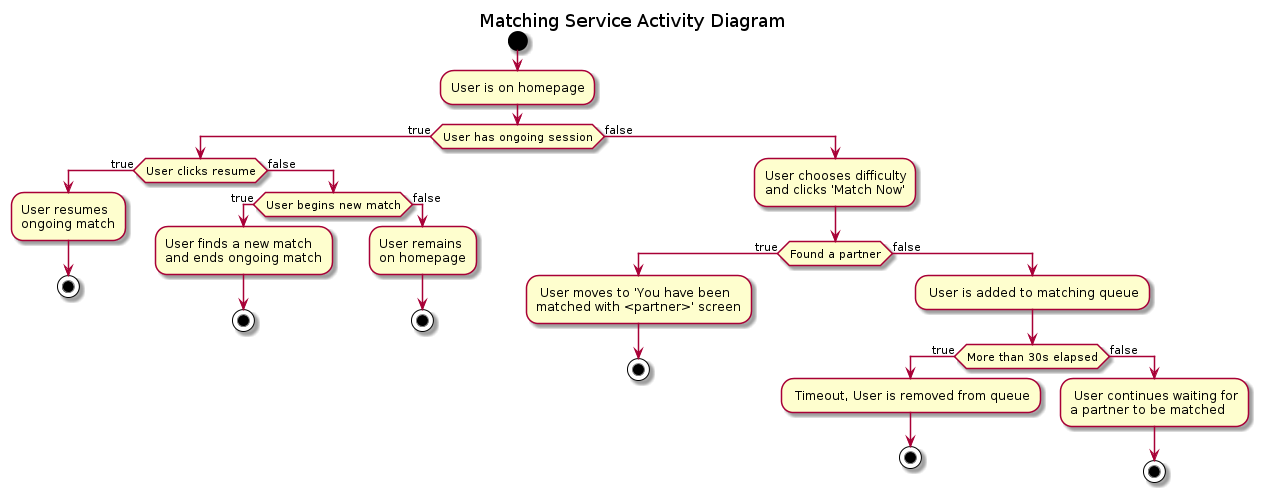 Activity Diagram for the Matching Service
Activity Diagram for the Matching Service
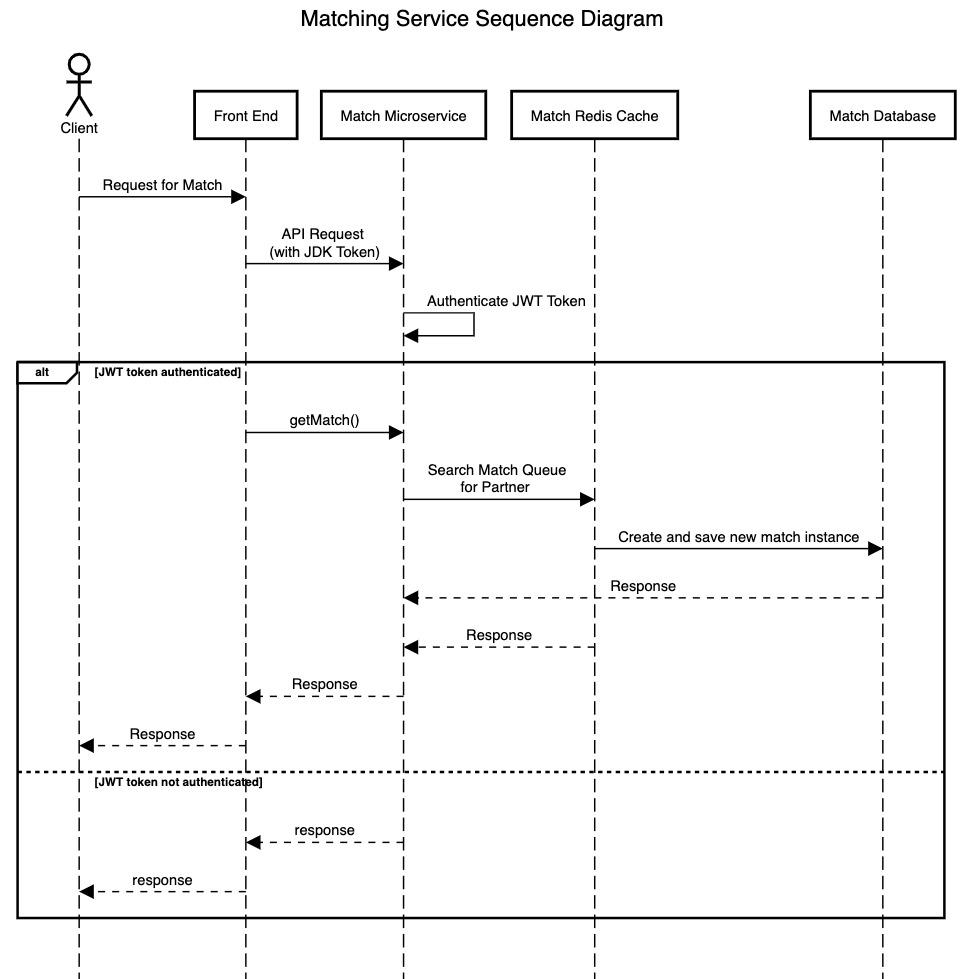 Sequence Diagram demonstrating getMatch() call
Sequence Diagram demonstrating getMatch() call
9.8.1 Supported Endpoints
All endpoints are authenticated and authorized with AWS Cognito JWT Token as a Bearer Token to confirm the identity of a valid user. All request body formats are JSON.
9.8.1.1 Matches endpoint:
To GET list of all matches, POST a new match or DELETE all matches
- [GET, POST, DELETE] HTTP request: https://www.api.peerprep.net/match/matches/

Diagram 9.1.2.1 Sample Example Of JSON Body Response after GET request
9.8.1.2 Usermatching Queue endpoint:
To GET the current queue, DELETE the entire queue or DELETE one queue entry by user details
- [GET, DELETE] HTTP request: https://www.api.peerprep.net/match/usermatching/
- To delete the entire queue, issue a
DELETErequest to this endpont - To delete one queue entry, issue a
DELETErequest with the email, username and difficulty level of the match request to be deleted to the endpoint https://www.api.peerprep.net/match/usermatching/delete - When a user clicks ‘Cancel Match’ after requesting for a match, this endpoint will be called allowing the user to cancel their search for matches when they are not yet allocated a match by the system (Functional Requirement F-RTD-3).

Diagram 9.1.2.2 Sample Example Of JSON Body Response after GET request to queue of 1 entry
9.8.1.3 Get Match endpoint:
To handle a POST request of a user requesting a match in the format:
{
"email":"",
"username":"",
"diff_lvl":"1"
}
- [POST] HTTP request: https://www.api.peerprep.net/match/getmatch/
- When the user chooses a difficulty level from the homepage, the frontend issues a
POSTrequest to this endpoint (Functional Requirement F-RTD-1). - Searches the queue for a match partner with the same requested difficulty level (Functional Requirement F-RTD-2).
- If found, returns partner’s details, unique room name and randomly assigned question of the requested difficulty level. Adds new match to Match Database.
- If not found, adds request to the back of the queue and returns JSON message ‘Unable to find a match, user added to queue’. If no partner is found after 30s, the request will timeout and be deleted from the queue.

Diagram 9.1.2.3 Sample Example Of JSON Body Response after a match partner is found
9.8.1.4 End Match endpoint:
To handle a POST request of a user ending their match in the format:
{
"email":"",
"room_name":""
}
- [POST] HTTP request: https://www.api.peerprep.net/match/endmatch/
- Decreases ‘active’ field in the Match object by 1. Initially, the ‘active’ field will be set to 2 to represent 2 active participants in the match.
- If ‘active’ field now becomes 0, this signifies that all participants have ended the match and the match is officially over. This will trigger calls to the Peer Programming API to delete the rooms that were used for the chat and video.
- The user that ended their match is added to the UserMatches database which holds a record of users’ past matches along with the date and time the user chose to end their match.
- An API call is also made to User Management service to increment the score of this user by the question score.
- Returns status code
200if everything flows correctly.
9.8.1.5 Get History endpoint:
To retrieve the list of all the officially over matches a user has participated in. Handles a POST request in the format:
{
"email":""
}
- [POST] HTTP request: https://www.api.peerprep.net/match/gethistory/
- Returns JSON representation of all the matches has participated in that have completely ended.

Diagram 9.1.2.4 Sample Example Of JSON Body Response after POST request with email e0418196@u.nus.edu
9.8.1.6 Deferred Match endpoint:
To handle a user currently waiting in queue and waiting to be matched with someone new who requests for a match and queries the queue. Handles a POST request in the format:
{
"email":"",
"username":"",
"diff_lvl":""
} * **[GET, POST, DELETE]** HTTP request: https://www.api.peerprep.net/match/deferred/ <br /><br /> * `GET` and `DELETE` are enabled to view and/or delete the list of deferred matches * This endpoint is for a user waiting in the queue to constantly query to find if someone new has found them as a match partner * Let the person waiting in the queue be A and the new request to be from person B. Returns:
{
"email1":"<A's email>",
"email2":"<B's email>",
"username1":"<A's username>",
"username2":"<B's username>",
"diff_lvl":"",
"room_name":"",
"qn":""
}
9.8.1.7 Find Active endpoint:
Finds active match based on email received in POST request in the format:
{
"email":""
} * **[POST]** HTTP request: https://www.api.peerprep.net/match/findactive/ <br /><br /> * One user should only have 1 active match at anytime. * If the requested user has more than 1 active match, this endpoint returns JSON message "User <email> has more than 1 active match. Terminated all matches." and status `200`. All active matches of that user are then terminated. * If the requested user has 0 active matches, this endpoint returns JSON message "User <email> has no current active matches." and status `200`. * If the requested user has 1 active match, this endpoint will return the details of that active match.

Diagram 9.1.2.5 Sample Example Of JSON Body Response after POST request with email of a user with 1 active match
9.8.1.8 Add Question endpoint:
To add questions, get list of all questions or delete all questions. Solely for testing/development purposes.
- [GET, POST, DELETE] HTTP request: https://www.api.peerprep.net/match/addqn/
- To get list of all questions, issue
GETrequest -
To add a new question, issue
POSTrequest in the format:{ "qn":"", "qn_diff_lvl":"" } - To delete all questions, issue
DELETErequest
Diagram 9.2.2.5: Sample Example Of Success JSON Response
10 Frontend
10.1 Frontend Tech Stack
- Vue JS 2
- Bootstrap Vue
- AWS CLI
- Firebase Realtime Database
- Firepad (Collaborative Editor)
- Daily Co (Video Conferencing)
- Twilio Conversations (Chat System)
10.2 Design Decision
After considering our team’s technical proficiencies, we decided to adopt Vue JS over React to develop our frontend user interface based on the following factors:
- Vue JS provides the option to use both HTML and JSX templates while React only offers Javascript Expressions (JSX).
- Vue has a traditional separation of concerns into HTML, JS and CSS. On the other hand, React’s JSX tend to combine both HTML and CSS with Javascript in a more XML-like syntax.
- Vue is designed to be incrementally adoptable from the ground up unlike other monolithic frameworks, hence providing us with future opportunities to integrate other open source web suites.
- Vue also has an abundance of tooling and supporting libraries.
- Hence, as none of us had any prior experience in frontend development, we decided to adopt Vue for our frontend development for its simpler syntax to minimise downtime derived from familiarization.
11 Application Screenshots
11.1 User Creation

Diagram 11.1.1: Landing Page

Diagram 11.1.2: Sign Up Page
PeerPrep Client automatically appends the .edu domain to provided on sign up to enforce F-UAM-1 and prevent emails outside our restricted domain from signing up.
The final used for registration can be seen in the green alert box above.

Diagram 11.1.3: Confirmation Page

Diagram 11.1.4: Confirmation Page Success
Upon sign up, client alerts AWS cognito to send a verfication email to the new user containing a confirmation code to ascertain their identity. They will then be required to enter this code into the above page. This models F-UAM-2 .

Diagram 11.1.5: Confirmation Page Error Invalid Code

Diagram 11.1.6: Confirmation Page Error Invalid User Password
Client handles data validation with cognito before approving user sign up.

Diagram 11.1.7: Login Page
Client validates User credentials with AWS Cognito and adds the user into our User Account Management MS as well before logging the user into our dashboard.

Diagram 11.1.10: Dashboard

Diagram 11.1.8: Confirmation Page Success

Diagram 11.1.9: Confirmation Page Error Invalid Code

Diagram 11.1.10: Confirmation Page Error Invalid User Password
Client handles data validation with cognito before approving user login.
11.2 Forget Password

Diagram 11.2.1: Forget Password

Diagram 11.2.2: Forget Password

Diagram 11.2.3: Confirmation email
AWS Cognito sends the user an email with a confirmation code upon request to reset password

Diagram 11.2.4: Forget Password

Diagram 11.2.5: Forget Password

Diagram 11.2.6: Forget Password

Diagram 11.2.7: Password Changed
11.3 Change Password

Diagram 11.3.1: Button to change password within dashboard

Diagram 11.3.2: Change Password page

Diagram 11.3.3: Change Password error
11.4 Update User Profile

Diagram 11.4.1: Button to update profile within dashboard

Diagram 11.4.2: Update profile page

Diagram 11.4.3: Profile updated and reflected
Client handles profile update by calls to our User Account Management API Endpoint.
11.5 Matchmaking

Diagram 11.5.1: Searching for match
User clicks the match now button and the client initiates a search with a 30 second timer countdown.

Diagram 11.5.2: Successfully matched
Upon successful match, the UI prepares to load the peerprogramming page

Diagram 11.5.3: Peer Programming Page
The user has the option to choose to join the video call and chat by clicking the respective join buttons

Diagram 11.5.4: Button to change password within dashboard
Users also have the option to toggle to dark mode with the button on the top left corner.

Diagram 11.5.5: Successful load of Video call session

Diagram 11.5.6: Share screen
Users are also allowed to share their screen with our conferencing application

Diagram 11.5.7: Button to enlarge video call screen

Diagram 11.5.8: Chat
Users can also enjoy real time chat functionalities as seen above. Our client achieves this via a link to twilio conversations API

Diagram 11.5.9: Code compilation
Users can execute and compile code as our client runs the compilation service with rapidapi.
Special code editor features

Diagram 11.5.10: Users can see each other code highlights

Diagram 11.5.11: Wrap text vertical

Diagram 11.5.12: Wrap text horizontal
11.6 Match History

Diagram 11.6.1: Match history table
The client makes orchestrates API calls to our User Account Management Service to retrieve match history and score data.

Diagram 11.6.2: Show Question from each history
11.6 Resume Active Match
To provide convenience for our users, we allow our users to resume matches in the event that they leave their programming page pre-maturely. Current active matches will only be ended on the following 3 conditions
- User clicks the
End Sessionbutton on the peer programming page - User starts a new match by clicking the
Match Nowbutton on the home page - User clicks the
End MatchButton on the home page.
Otherwise, our client preserves the session and allows users to refresh their active match page without losing their session.

Diagram 11.7.1: Resume Match
12 Suggested enhancements
One enhancement would be adding users to add past matches as friends and build a friend system for the application. Users should also be allowed to match directly with their friends. This would make the project more enticing and interesting for more users. It will also incentivise current users to invite their friends and learn together.
Another enhancement is to allow more students to match together to work on the questions. However, that will be pose its own challenges as we will have to coordinate matches of different group sizes and different users dropping in and joining back matches.
13 Reflections and Learning Points
-
It is crucial to start integration early. Being used to monolithic architectures, we focused heavily on the functional aspect at the start only to be met by difficult integration issues towards the end of the project. As such, many sleepless nights were spent trying to fix these issues.
-
Budgetting is difficult. Up til now, we did not have to consider costs when building a project. Towards the end of the project, we realized the costs we were racking up were unpredictable and we were afraid of overshooting the budget. This was a stark reflection of the future industry, where every decision will come with some cost, often financial.
-
Communication is key. Constant and frequent updates and communication between the group members is important. We should always be updated on what each other are doing even though we are in charge of our own microservice.